Sentiment Analysis
Predict sentiment from text.
Inputs
Corpus: A collection of documents.
Outputs
Corpus: A corpus with information on the sentiment of each document.
Sentiment Analysis predicts sentiment for each document in a corpus. It uses Liu & Hu and Vader sentiment modules from NLTK, multilingual sentiment lexicons from Chen and Skiena, SentiArt from Arthur Jacobs, and LiLaH sentiment from Walter Daelemans et al. All of them are lexicon-based. For Liu & Hu, you can choose English or Slovenian version. Vader works only on English. Multilingual sentiment supports several languages, which are listed at the bottom of this page. SentiArt works on English and German. LiLaH sentiment supports Slovenian, Croatian, and Dutch. Custom dictionary enables one to upload custom positive and negative sentiment dictionaries. Custom files should be plain text files (.txt) with each word in its own line.
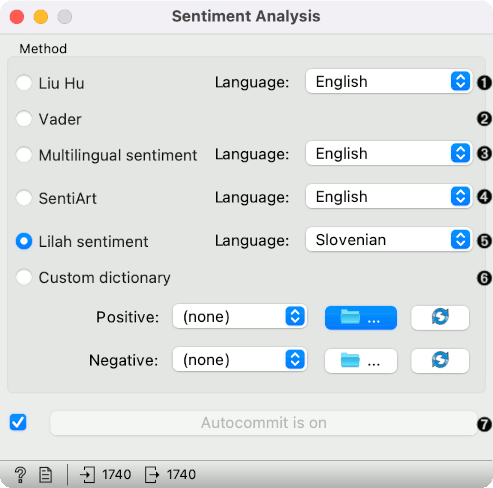
Liu Hu: lexicon-based sentiment analysis (supports English and Slovenian). The final score is the difference between the sum of positive and sum of negative words, normalized by the length of the document and multiplied by a 100. The final score reflects the percentage of sentiment difference in the document.
Vader: lexicon- and rule-based sentiment analysis
Multilingual sentiment: lexicon-based sentiment analysis for several languages
SentiArt: sentiment analysis based on vector space models returning text valence
LiLaH sentiment: manual translations of the NRC Emotion Lexicon
Custom dictionary: add you own positive and negative sentiment dictionaries. Accepted source type is .txt file with each word in its own line. The final score is computed in the same way as Liu Hu.
If Auto commit is on, sentiment-tagged corpus is communicated automatically. Alternatively press Commit.
Example
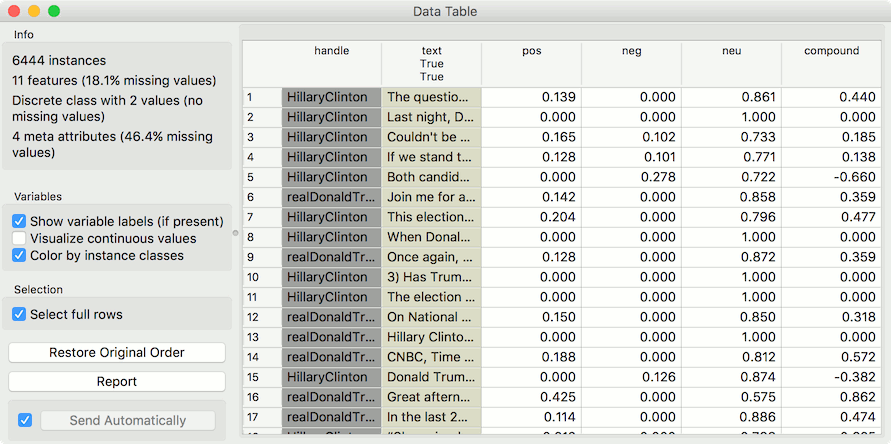
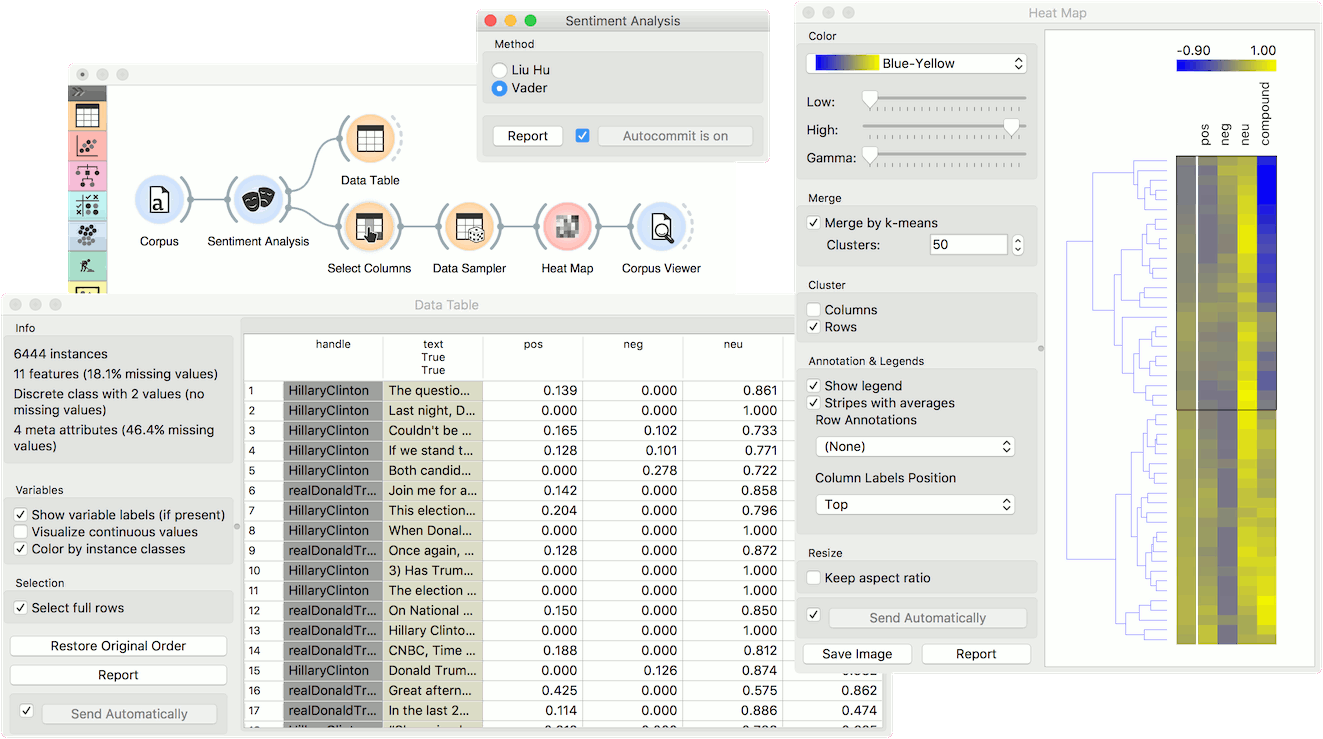
Sentiment Analysis can be used for constructing additional features with sentiment prediction from corpus. First, we load Election-2016-tweets.tab in Corpus. Then we connect Corpus to Sentiment Analysis. The widget will append 4 new features for Vader method: positive score, negative score, neutral score and compound (combined score).
We can observe new features in a Data Table, where we sorted the compound by score. Compound represents the total sentiment of a tweet, where -1 is the most negative and 1 the most positive.
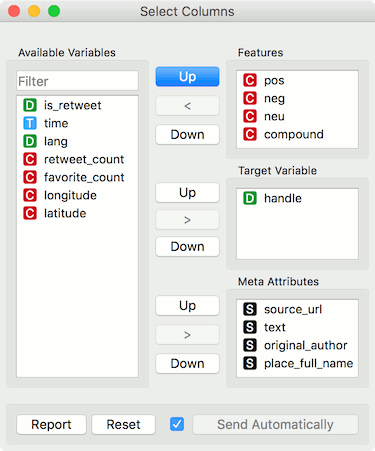
Now let us visualize the data. We have some features we are currently not interested in, so we will remove them with Select Columns.
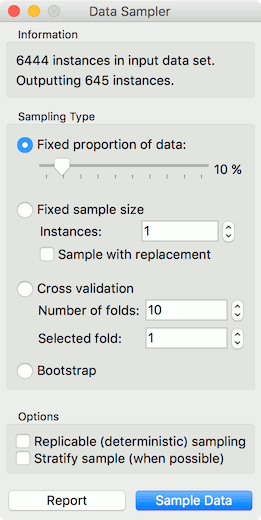
Then we will make our corpus a little smaller, so it will be easier to visualize. Pass the data to Data Sampler and retain a random 10% of the tweets.
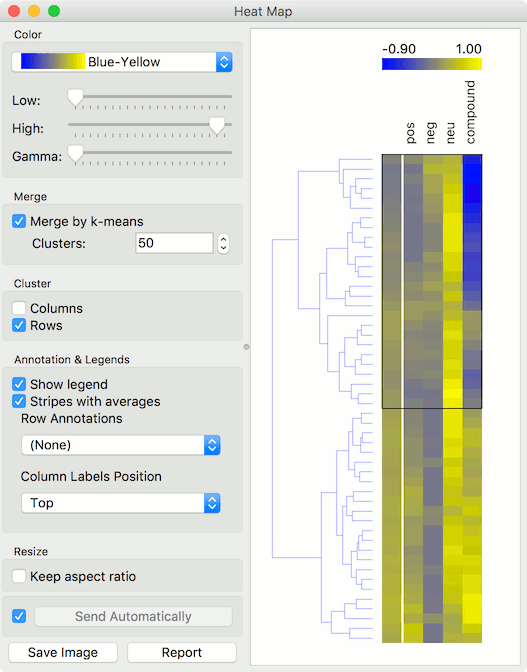
Now pass the filtered corpus to Heat Map. Use Merge by k-means to merge tweets with the same polarity into one line. Then use Cluster by rows to create a clustered visualization where similar tweets are grouped together. Click on a cluster to select a group of tweets - we selected the negative cluster.
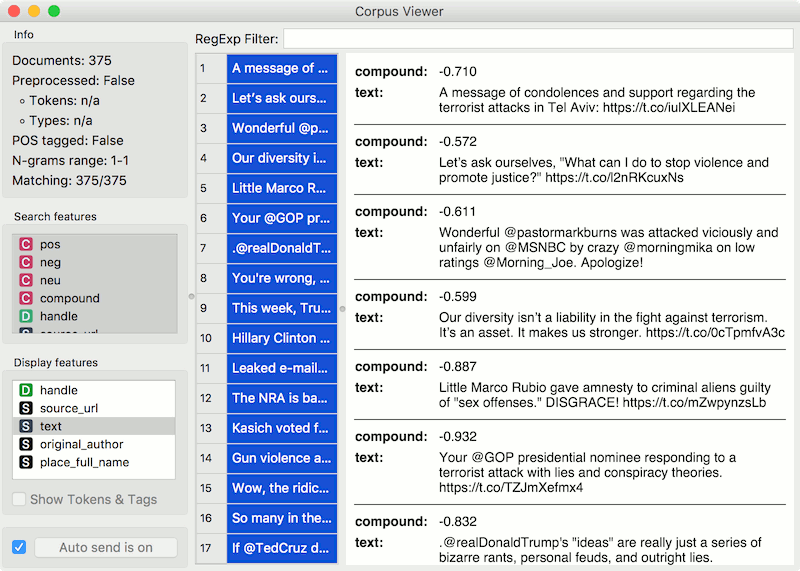
To observe the selected subset, pass the tweets to Corpus Viewer.
References
Hutto, C.J. and E. E. Gilbert (2014). VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. Eighth International Conference on Weblogs and Social Media (ICWSM-14). Ann Arbor, MI, June 2014.
Hu, Minqing and Bing Liu (2004). Mining opinion features in customer reviews. In Proceedings of AAAI Conference on Artificial Intelligence, vol. 4, pp. 755–760. Available online.
Jacobs, Arthur M. (2019). Sentiment Analysis for Words and Fiction Characters From the Perspective of Computational (Neuro-)Poetics. Frontiers in Robotics and AI 6. https://doi.org/10.3389/frobt.2019.00053
Kadunc, Klemen and Marko Robnik-Šikonja (2016). Analiza mnenj s pomočjo strojnega učenja in slovenskega leksikona sentimenta. Conference on Language Technologies & Digital Humanities, Ljubljana (in Slovene). Available online.
Ljubešić, Nikola, Ilia Markov, Darja Fišer and Walter Daelemans (2020). The LiLaH Emotion Lexicon of Croatian, Dutch and Slovene. In Third Workshop on Computational Modeling of People’s Opinions, Personality, and Emotion’s in Social Media (PEOPLES 2020), pp. 153–157. Available online.
Multilingual Sentiment Languages
Afrikaans
Arabic
Azerbaijani
Belarusian
Bosnian
Bulgarian
Catalan
Chinese
Chinese Characters
Croatian
Czech
Danish
Dutch
English
Estonian
Farsi
Finnish
French
Gaelic
German
Greek
Hebrew
Hindi
Hungarian
Indonesian
Italian
Japanese
Korean
Latin
Latvian
Lithuanian
Macedonian
Norwegian
Norwegian Nynorsk
Polish
Portuguese
Romanian
Russian
Serbian
Slovak
Slovene
Spanish
Swedish
Turkish
Ukrainian